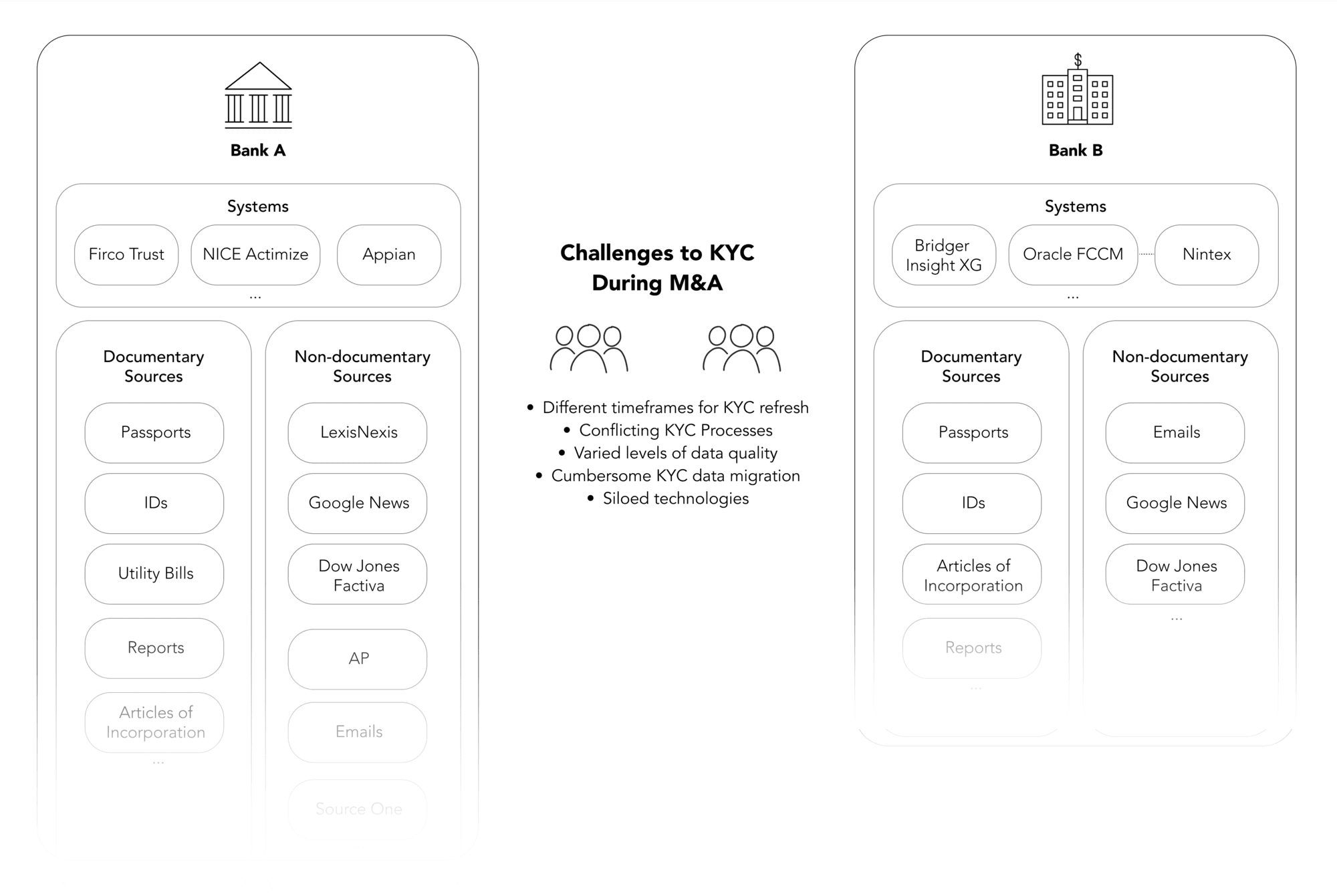
The Core Challenges to KYC During M&A
Challenge #1: Conflicting KYC Processes between FIs No two FIs will follow exactly the same KYC process. While their general KYC process may appear similar from a high-level vantage point, each follows its own unique multi-step journey that involves disparate information systems and typically requires a number of touchpoints, depending on the line of business and customer type, for handling a wide variety of documentary and non-documentary data sources.
Whether because they serve different geographies, offer varied products, or have dissimilar customer types, merging FIs often do not share the exact same KYC process. A significant difference often exists in the sources of information they use to perform KYC. For example, one institution may not conduct batch screening for negative news about its customers on a periodic basis, and only during the refresh cycle, while the other one performs negative news screening on every customer and related party in a nightly or monthly batch. Similarly, one FI may update (KYC refresh) customer data on a 1/2/3-year refresh cycle, while the second one might be on a 1/3/5-year refresh cycle. In the end, KYC process variation between the two FIs causes major issues around data migration and data quality when merging operations, and typically requires manual intervention to manage and mitigate the risks.
Challenge #2: Poor data quality As noted earlier, the two FIs may not have been capturing similar data points or documentation considering their lines of business, customer types, or geographical footprint and varying KYC requirements. Varying strengths of KYC programs may also factor in where one FI is further advanced in its KYC requirements and workflow as well as its Customer Risk Rating model. For example, there may exist gaps in documentary and non-documentary KYC data. According to McKinsey, many institutions perform manual KYC outreach. “Data are then copied over into KYC workflow tools,” McKinsey noted. “These tasks are often seen as low value, an attitude that leads to institutional inattention—which tends to increase the chance of errors.”
The lack of quality data collected in the customer due diligence (CDD) process can expose an FI to regulatory risk. If information obtained at account opening is not comprehensive and accurate, it becomes difficult to assign the appropriate risk score to a customer. This issue can be compounded when onboarding thousands, if not millions, of new customers during an acquisition.
IDP (intelligent document processing) was seen as a solution to the challenge of comprehensive data collection. Yet, even with traditional IDP tools, data gaps exist when the IDP solution itself does not incorporate both knowledge-based AI and ML-based AI.
According to Forrester, knowledge-based AI should exist in modern IDP tools (referred to as IDEP by Forrester), meaning that the IDP solution should arrive with rules already defined for KYC data identification, extraction, and classification, with knowledge already incorporated into it. That is the ‘knowledge-based AI’ portion. The second type of AI, ML-based AI, uses machine learning (ML) to analyze the content and context of different data points for continuous improvement. This enables IDP to further optimize the extraction and processing of data from semi-structured sources (e.g., articles of incorporation and trust agreements) and unstructured sources (e.g., emails and public news sources). The over-reliance on forms data can limit the efficacy of KYC due diligence.
Operations teams are also accustomed to everyday challenges in document handling. For example, they capture large volumes of client records. Yet, it is difficult to discern from which field or document certain information originated – whether it came from an identity document, an incorporation document, a shareholder update, or any of the other hundreds of information sources. This places a substantial burden on the operations teams who inevitably face document handling constraints in terms of massive volumes, the large number and variety of documents, and a lack of tools.
Moreover, with many documents in PDF format, an IDP tool that lacks powerful NLU (natural language understanding) provides little insight into the detailed information within those PDFs. This is often the case with semi-structured documentation like articles of incorporation.
Without strong NLP, machine learning suffers (and is essentially nonexistent) in an IDP solution. This has a downstream adverse impact on automating KYC operations, because the incomplete, inaccurate and/or outdated information presented by IDP requires an excess of manual checks or extractions on the data during KYC workflow processes. Here, the expression of ‘garbage in, garbage out’ applies to the information first collected via IDP and then presented to downstream KYC processes.
Natural language processing makes it possible for computers to extract keywords and phrases, understand the intent of language, translate that to another language, or generate a response. NLP itself has a number of subsets, including natural language understanding (NLU), which refers to machine reading comprehension.
Signs of incomplete document handling capabilities
Challenge #3: Cumbersome KYC data migration Customer data resides in many systems, often within 10 or more. As a result, consolidating data from two FIs during a merger or acquisition is both complex and labor-intensive. For the two FIs involved, the individual KYC teams each rely on their own databases of information, and merging those two databases still presents major challenges. It requires additional staff, lots of time, and double the work to populate the final results into a single system to be used for KYC. Additionally, a lot of IT work gets wasted and never reused. For example, IT has to write temporary scripts to move data between systems. Adding to the effort is their need to evaluate the latest tools and set priorities for data movement. Not only is the entire ordeal a one-off, inefficient effort, it all gets thrown away once the data migration is completed. This can take years of complex activity for little long-term ROI.
Challenge #4: Non-integrated technologies in the KYC process Consolidating KYC information during a merger is challenging enough without having to integrate a disparate technology stack that drives KYC workflows and processes. Too often, a bank has one tool (or manual effort) for IDP, another to make decisions about the data, a third tool to automate workflows, and a plethora of tools to make those automations work with core systems.
Not only are the initial integrations complicated and expensive, once each tool used in the KYC process updates to a new version or a new tool is added to the mix, every interacting tool must be re-integrated to ensure that all the various versions of software continue to operate in unison.
This type of ongoing software maintenance and integration cannot be performed by line-of-business professionals. It requires ongoing commitment from IT, despite many software vendors’ claims that their tools require little to no coding experience. That may be true for an individual solution, but integration expertise is an expensive and increasingly hard-to-source item. KYC teams could find themselves in a bind when competing against a banks’ revenue-generating departments for IT resources when they need to integrate – both during and after the merger.
The Risks of a KYC technology architecture without seamless integration:
Fortunately, the four challenges to robust KYC during M&A are no longer insurmountable, and FIs no longer need to settle for increased risk exposure during that time. Technological advances found in WorkFusion AI Agents (developed specifically for KYC operations) now enable FIs to follow a best-practices approach to KYC – both architecturally and technologically. Read on for that approach.